How to Build an AI Product That Pulls From Multiple Data Sources (Without Breaking in Production)
How to Build an AI Product That Pulls From Multiple Data Sources (Without Breaking in Production)
Most AI products that aggregate data from multiple external sources don't fail because of the model. They fail because nobody made the right architecture decisions in week one. By the time the product reaches real users, the data inconsistencies, validation gaps, and brittle integrations are already embedded in the codebase.
The demo worked. The product doesn't.
This is one of the most common failure patterns we see when teams come to us after a build that didn't hold. The problem isn't the AI layer. It's everything underneath it: how data is ingested, normalized, validated, and surfaced to users under real conditions.
This post covers the specific architecture and delivery challenges that come with building AI products over multiple external data sources — and what it actually looks like to get it right, using Landable as a concrete example.
Why Multi-Source AI Products Break Before They Scale
The demo-to-production gap
A prototype that pulls from two or three sources and works in a controlled environment is not the same product as one that reliably aggregates eight sources under variable network conditions, changing API schemas, and concurrent user load.
The OECD found that the majority of AI deployments across the EU public sector are still in pilot or development phases, not in production. That's not a funding problem. It's an architecture problem. Moving from a demo that convinces to a product that survives requires a different class of decisions.
The gap shows up in three places: data inconsistency across sources, failure handling when a source is unavailable or returns unexpected formats, and output reliability when the data feeds into user-facing elements like exported PDFs or visual maps. Each of those is a design decision, not a technical accident.
What "8 data sources" actually means architecturally
Each external source is its own contract. Government data portals, zoning APIs, parcel registries — they have different schemas, different update cadences, different reliability profiles, and different authentication patterns. Some have no API at all.
When you're building a product that aggregates data from sources like these, you're not building one integration. You're building eight, each with its own edge cases, and then building the normalization layer that makes them interoperable. That work doesn't appear in a demo. It's what separates a functional prototype from a product that holds.
The Architecture Decisions That Determine Everything
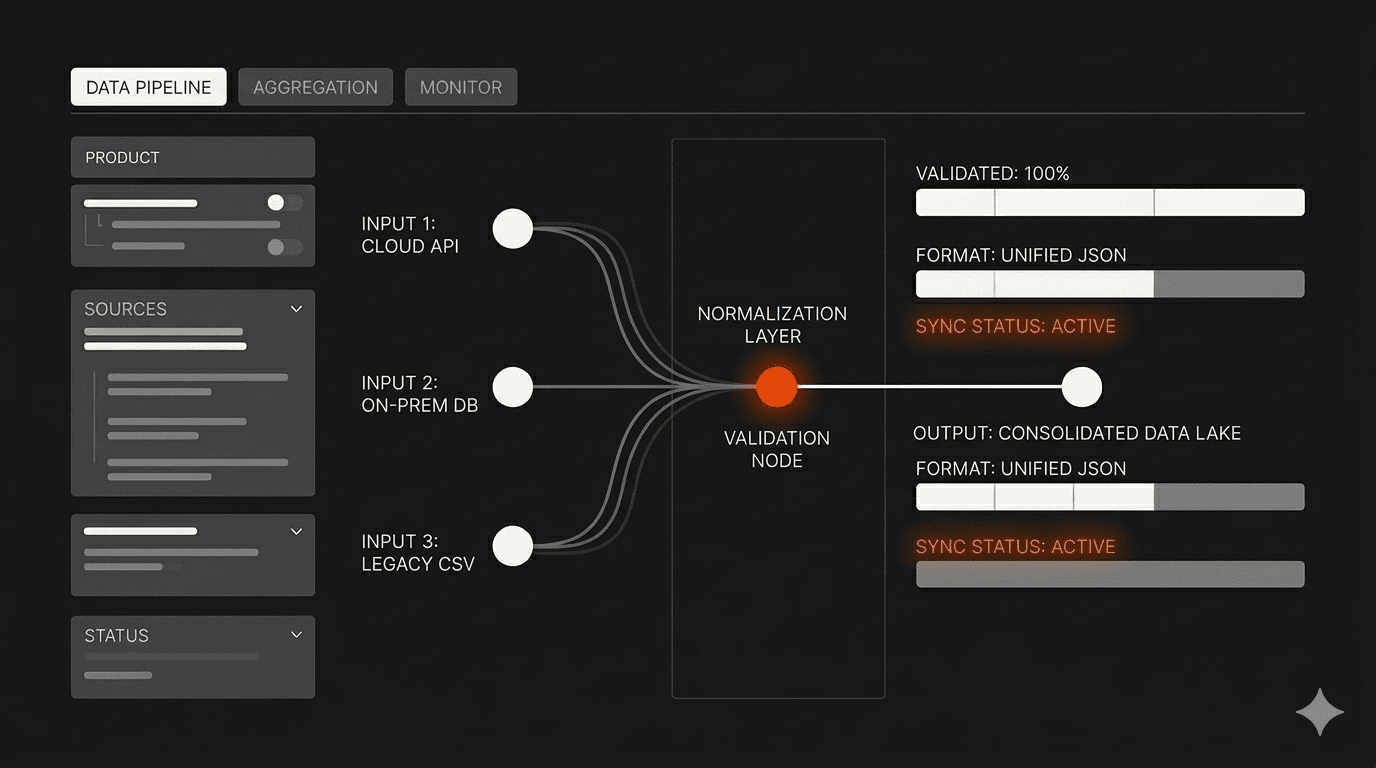
Normalization and schema design before you write a line of AI logic
The most common mistake is writing AI logic before defining a stable internal data schema. If your AI layer is consuming raw data directly from external sources, every schema change upstream breaks the product.
The right sequence: define your internal data model first, build normalization adapters for each source, and let your AI logic operate only on the normalized schema. This adds time at the start. It removes weeks of rework later. This is the kind of week-one architecture decision that determines whether a four-week build is possible without cutting corners.
How to handle inconsistent or missing data from government and public sources
Government data sources are not designed for programmatic consumption. Fields that should be standardized aren't. Data that should be current isn't. Records that should exist don't.
Your product needs a clear policy for each of these cases before the first user interacts with it. What does the UI show when a parcel has no zoning record? What happens when a source returns a 200 with malformed data? These aren't edge cases, they're recurring conditions in any system that depends on public data infrastructure.
A validation layer that sits between source ingestion and AI processing is non-negotiable. It should classify data quality, flag incomplete records, and surface confidence signals to users rather than silently passing bad data downstream.
Validation layers that catch errors before users do
Data errors in a government context carry real consequences. A land developer making a submission decision based on incorrect zoning data, a wrong flood plain classification, or a mismatched parcel boundary doesn't just get a bad user experience. They make a costly business decision on corrupted information.
Research from KPMG found that 62% of organizations identify a lack of data governance as the main challenge inhibiting their AI initiatives. For products operating on public data sources, that governance has to be built into the product itself, not assumed from the sources.
The validation architecture has to run checks at ingestion, flag anomalies in the normalization step, and give users accuracy signals before they act on the data. That design choice affects the entire pipeline, not just a single component.
How We Built Landible: An AI Platform That Auto-Fills RFIs From 8+ Government Sources
The problem: days of manual research for every submission
Land developers completing government RFIs face a workflow that hasn't changed in years: collect data from multiple government portals, match it to the format required by each agency template, validate it manually, coordinate feedback across teams, and export it in whatever format the receiving agency accepts.
A single RFI can require data from zoning registries, parcel databases, flood plain records, and environmental surveys, each from a different source, each in a different format. For smaller development firms, this means dedicating staff to research that larger players absorb more easily. Projects stall. Data errors are costly. And the process repeats for every new submission.
The build: template-agnostic ingestion, automated validation, visual mapping
The Landable platform accepts any RFI template format, not just a fixed set of supported templates. This was a deliberate product decision with real architecture implications. The ingestion layer has to parse the structure of an unknown document, identify which fields need to be populated, and match them to the appropriate data sources before any AI logic runs.
From there, the platform auto-fills fields from 8+ authoritative government sources: parcel registries, zoning classifications, flood plain data, environmental records, and others. Each source goes through the normalization and validation pipeline. The product then surfaces visual overlays for zoning boundaries, flood plains, and parcel lines, giving users spatial context to review auto-filled data before exporting.
Output is export-ready: PDF and CSV formats compatible with any agency's receiving system. The full case study is on our site: Landable — Land Use, Automated.
The result: 428% time savings, no headcount expansion
The platform delivered a 428% reduction in RFI completion time. Data accuracy improved through automated validation replacing manual cross-referencing. Teams using it now manage multiple projects simultaneously without adding research staff.
The competitive implication is real: smaller firms now have access to the same authoritative data sources that enterprise players use internally. The data advantage disappears. The execution speed advantage shifts to the firm with the better workflow.
What Production-Ready Looks Like for This Type of Product
The Bug Bash: breaking the product before real users do
Two weeks before every delivery, we run a Bug Bash: the team and the client sit together and actively try to break the product. Not a QA checklist. An adversarial session designed to find what fails under real-use conditions before the product reaches actual users.
For a multi-source data product like Landable, that means testing what happens when a source returns unexpected data, when a template structure doesn't match the expected schema, when a user exports a record with incomplete fields. The scenarios that feel unlikely in a controlled environment are exactly the ones that happen first in production.
Pen testing on critical features follows. Then delivery.
This process is what separates a product that holds from one that generates support tickets on day two. For a product where data accuracy has direct business consequences, it isn't optional.
Export reliability: the last thing teams think about, the first thing users notice
In a product like Landable, the output is a document submitted to a government agency. The export has to be correct every time, right format, right field mapping, right data values.
Most teams treat export functionality as a finishing step. It's not. The export format requirements should inform the data model from the beginning. If you're designing backwards from a PDF or CSV that has to meet agency specifications, the entire normalization and validation pipeline needs to account for those output constraints. Building the export layer last means rebuilding parts of the pipeline when the constraints surface.
We've seen this pattern across enough multi-source data products — including our work on MeasureAI's multi-model AI architecture for HVAC analysis and CaseBench's dental case workflow platform — to treat export design as a week-one requirement, not a final integration task.
Frequently Asked Questions
How long does it take to build a production-ready multi-source AI platform?
It depends on the number of sources, their reliability, and the output requirements. A product pulling from 3 to 5 well-documented APIs with standardized schemas can reach production-ready state in 4 to 6 weeks with the right architecture decisions upfront. A product pulling from 8+ sources — especially government data with inconsistent schemas and limited API support — takes longer, primarily because of the normalization and validation work that precedes the AI layer.
The variable that matters most isn't the number of sources. It's whether the team defines the internal data model before writing integration code. Teams that skip that step typically spend the back half of the build refactoring the front half.
Our average MVP timeline across 50+ products is 4 weeks. That's the result of making the right architectural decisions in week one, not of moving faster through the wrong ones.
What's the hardest part of integrating with government data sources?
Consistency. Government data portals weren't designed for programmatic access. Documentation is often incomplete or outdated. Schema changes happen without notice. Some records are missing. Some are duplicated. Some are correct in one source and incorrect in another.
The hardest problem isn't connecting to the source — it's deciding what to do when the source returns something unexpected. That decision has to be made deliberately, documented, and reflected in the product's UI. Users need to know the confidence level of the data they're acting on.
Products that don't solve this either show users incorrect data silently, or show them errors that erode trust. Neither is acceptable in a domain where data accuracy has direct business consequences.
When should you build in-house vs. partner with an AI development studio?
Build in-house if you have a senior engineer who has built production AI systems on top of external data sources before, and if your team has capacity to make it the primary focus for two to three months without diverting to other priorities.
Partner with a studio if that capacity doesn't exist, if the product needs to reach market before a window closes, or if the architectural decisions required are outside your team's current experience. The cost of rebuilding a product that was architected wrong in week one is always higher than the cost of getting the architecture right from the start.
Our process is available for teams evaluating what a partnership looks like in practice.
What This Pattern Tells Us About Building AI on Regulated Data
Landable is one product in one vertical. But the pattern it represents — an AI product that aggregates fragmented, inconsistently formatted public data and surfaces it as a reliable, validated, export-ready output, applies to almost every industry operating on regulated or government-adjacent data.
Healthcare, financial services, construction, environmental compliance, real estate: all of them share the same underlying problem. The data exists. It's fragmented across sources that weren't designed to work together. And the teams trying to build on top of it are discovering that the AI layer is the easy part.
The hard part is the architecture that makes the AI layer trustworthy.
At Imaginary Space, we've shipped 50+ AI products across environments like these. If you're building in a domain where data reliability and output accuracy aren't optional, we're at imaginaryspace.ai.