How We're Engineering the AI Brain Behind MeasureAI
How We Built the AI Engine Behind MeasureAI — A Real Construction Takeoff System
Most software that claims to automate construction takeoffs is a better-looking spreadsheet with an OCR layer on top. You upload a PDF, it reads some numbers, you spend the next hour fixing what it missed. That's not AI construction takeoff software. That's digitized manual work.
MeasureAI is different — and the reason comes down to architecture.
We built the AI engine behind MeasureAI, a takeoff and cost-estimating platform built specifically for ventilation and HVAC professionals in the UK market. The system doesn't assist an estimator through a drawing. It reads the drawing, identifies every component, classifies it, measures it, and generates a complete takeoff — with a human review layer for edge cases the system flags itself.
This post is a technical breakdown of how we built it: the problems we had to solve, the architecture we chose, and what it taught us about building production-ready AI for a vertical that hasn't changed in decades.
Why HVAC Takeoff Is Harder to Automate Than It Looks
A ventilation engineer receiving a set of 2D PDF drawings today does roughly the same thing engineers did twenty years ago. They print the drawings — or open them on screen — trace ductwork runs manually, count fittings, and transfer everything into a spreadsheet. On a complex project, that process takes days.
AI estimating tools that process plan sets can reduce a task that takes an experienced estimator 6–8 hours down to under 15 minutes. But hitting that benchmark for HVAC specifically requires solving three distinct problems in sequence — and most platforms are only solving one of them cleanly.
The first is scale detection. Before any measurement is possible, the system needs to know what scale the drawing is at. This sounds like a solved problem. It isn't. Architectural and engineering drawings embed scale information inconsistently — sometimes in the title block, sometimes in gridline spacing, sometimes in dimension annotations, and sometimes in combinations of all three that contradict each other. A system that gets scale wrong doesn't produce a slightly off measurement. It produces measurements that are systematically wrong in ways that aren't immediately obvious — and that only surface when a bid is submitted and someone notices the ductwork quantities don't match the building.
Why a single model can't solve this
The second and third problems are component detection and classification. Detection answers the question: where is the thing? Classification answers: what is the thing? These are related but structurally different tasks.
Detection models — architectures like YOLO and RT-DETR — are fast and accurate at locating objects in an image. But they don't reliably distinguish between a fire damper and an attenuator when both appear as similar symbols at small scale on a dense drawing. Classification models handle that discrimination well, but they require the object to already be isolated and cropped. And neither detection nor classification models handle the text and numeric annotations that connect a component to its specification — dimension labels, duct sizes, flow rates — because that's an OCR problem.
Three problems. Three model families. One pipeline that has to produce a single coherent output.
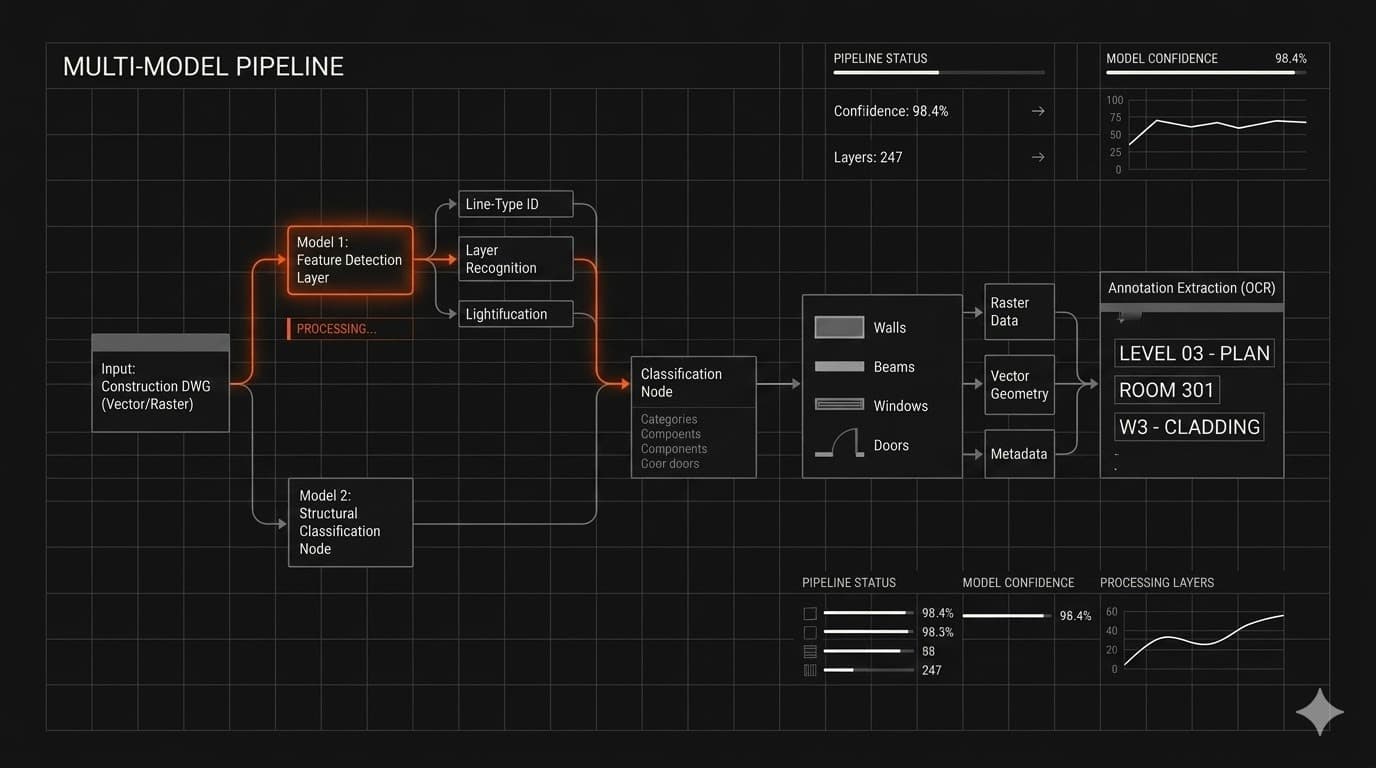
The Multi-Model Architecture We Built
The core of MeasureAI is what we call the AI Takeoff Engine — an ensemble architecture that uses different model types for each layer of the problem, then combines their outputs into a unified result.
Detection, classification, and OCR as separate layers
The detection layer uses object detection and segmentation models (drawing on YOLO-family and RT-DETR architectures) to identify where HVAC components appear in the drawing. The classification layer uses CNN-based classifiers — ResNet and EfficientNet equivalents — to determine what each detected object is. The OCR layer extracts labels, dimensions, and annotations directly from the drawing and links them to the classified components.
Each layer is optimized for its specific task. None of them are expected to solve the other layers' problems.
How the ensemble logic ties it together
The outputs of the three layers feed into a weighted confidence scoring system. Every identified component carries a confidence score from each model that contributed to its classification. The ensemble logic uses those scores to produce a final determination — and flags any component where confidence falls below a defined threshold rather than making a guess.
Rules-based post-processing then handles the edge cases that probabilistic models handle poorly: duplicate detections at component boundaries, overlapping annotations, and components that appear differently across different drawing styles or conventions. This is where a lot of AI systems that look good in demos start to break. The model works on the training distribution. The rules handle everything else.
Why we chose this approach over a monolithic model
A single end-to-end model trained to go from raw PDF to completed takeoff is theoretically possible. It's also significantly harder to debug, harder to improve incrementally, and harder to expand to new component types or new trades.
The ensemble approach means each layer can be retrained or replaced independently. When MeasureAI adds electrical takeoff or plumbing — which the architecture is designed to support from day one — the detection and OCR layers remain largely unchanged. Only the classification layer needs to learn the new component vocabulary.
That decision matters more for a product that needs to grow than for a demo that needs to impress.
What Production-Ready Means for an AI Takeoff System
Production-ready is a term that gets used loosely. For MeasureAI, it has a specific meaning: the system has to be correct enough, consistently enough, that a professional puts their name on the output.
The ≥98% scale detection accuracy requirement
Scale detection has to be right at least 98% of the time. That's not an aspirational target — it's the threshold below which the error rate in downstream measurements becomes commercially unacceptable.
The system detects scale using three independent signals: scale legends in the title block, gridline spacing, and dimension annotations. If those signals produce a reading that deviates by more than 3%, the drawing gets flagged for manual validation rather than processed automatically. The system knows what it doesn't know — and stops rather than proceeding on bad input.
Automated takeoff at this level isn't just a speed play; it functions as a risk-control mechanism for preconstruction. Getting quantities wrong at the takeoff stage means getting bids wrong, which means either losing margin or losing work. The accuracy requirement isn't about product quality in the abstract — it's about whether the output is actually usable in a commercial context.
Henry Roberts, the client behind MeasureAI, described the moment the AI component worked in production for the first time: "This is the bit that I was most scared about and I think it was the riskiest part for me to see it work. It's amazing." That reaction — relief as much as excitement — is what production-ready actually looks like from the client side.
Handling edge cases, duplicates, and overlap resolution
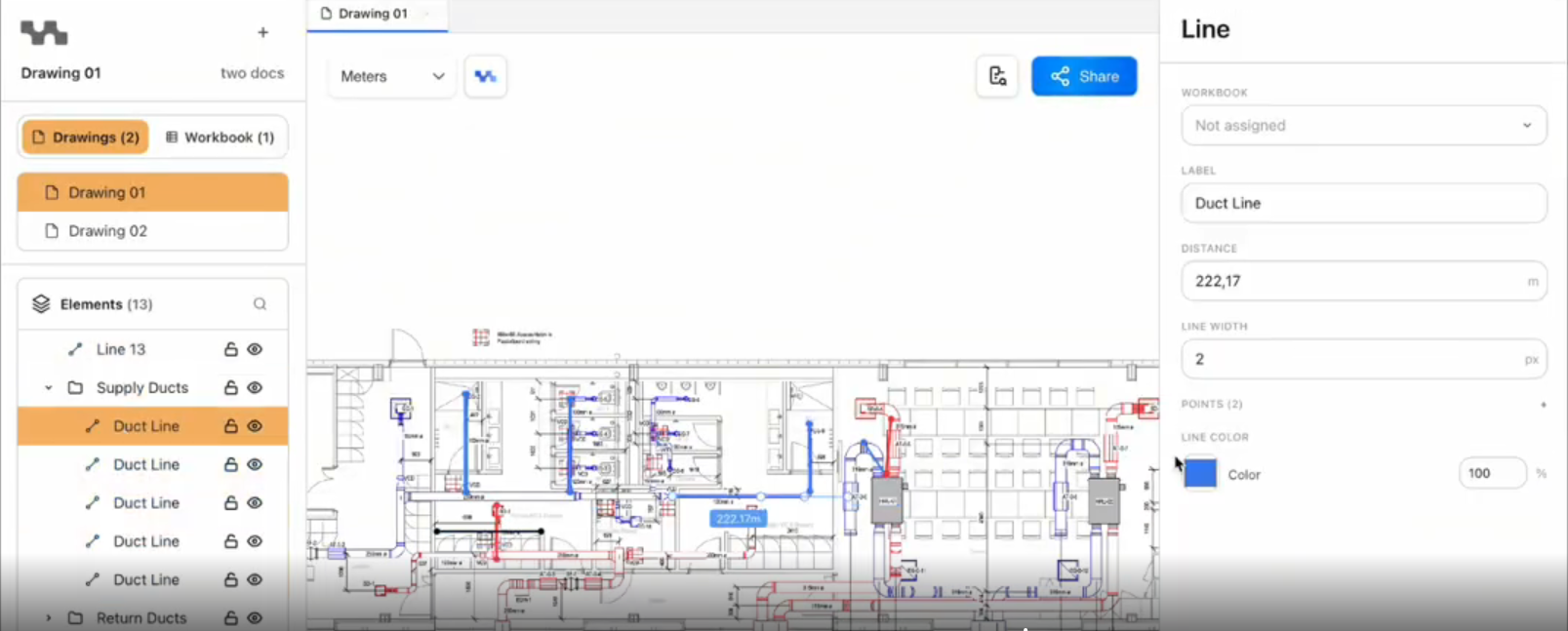
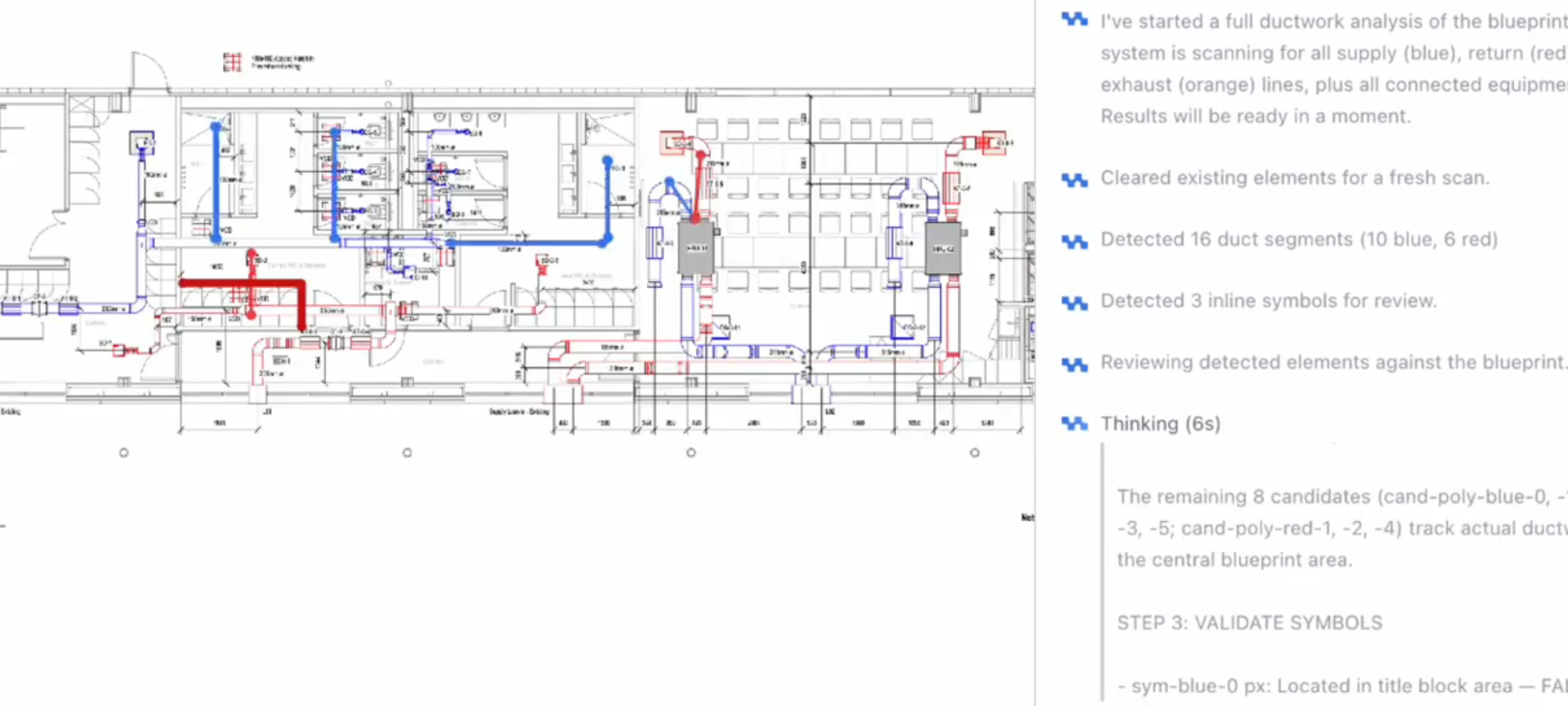
A system that works on clean drawings isn't a system. Most real drawings aren't clean. They have overlapping annotations, inconsistent symbol libraries, handwritten additions, and components that span multiple sheets.
The post-processing layer handles this. Duplicate detections — where the same component is identified twice because it sits at the boundary between two detection regions — are resolved through an overlap threshold algorithm. Conflicting annotations are surfaced for human review rather than arbitrated automatically. The Co-Pilot Review Panel gives estimators a direct interface to review, correct, and confirm any output the system flags as uncertain.
The goal isn't a system that never needs human input. The goal is a system that directs human attention to exactly the right places — and handles everything else without it.
Designing for expansion beyond HVAC from day one
The MVP detects and measures a minimum of 15 core component types: supply and return air ductwork, fire dampers, diffusers, attenuators, DW144 hanger bracket calculations, and more. But the architecture doesn't stop there.
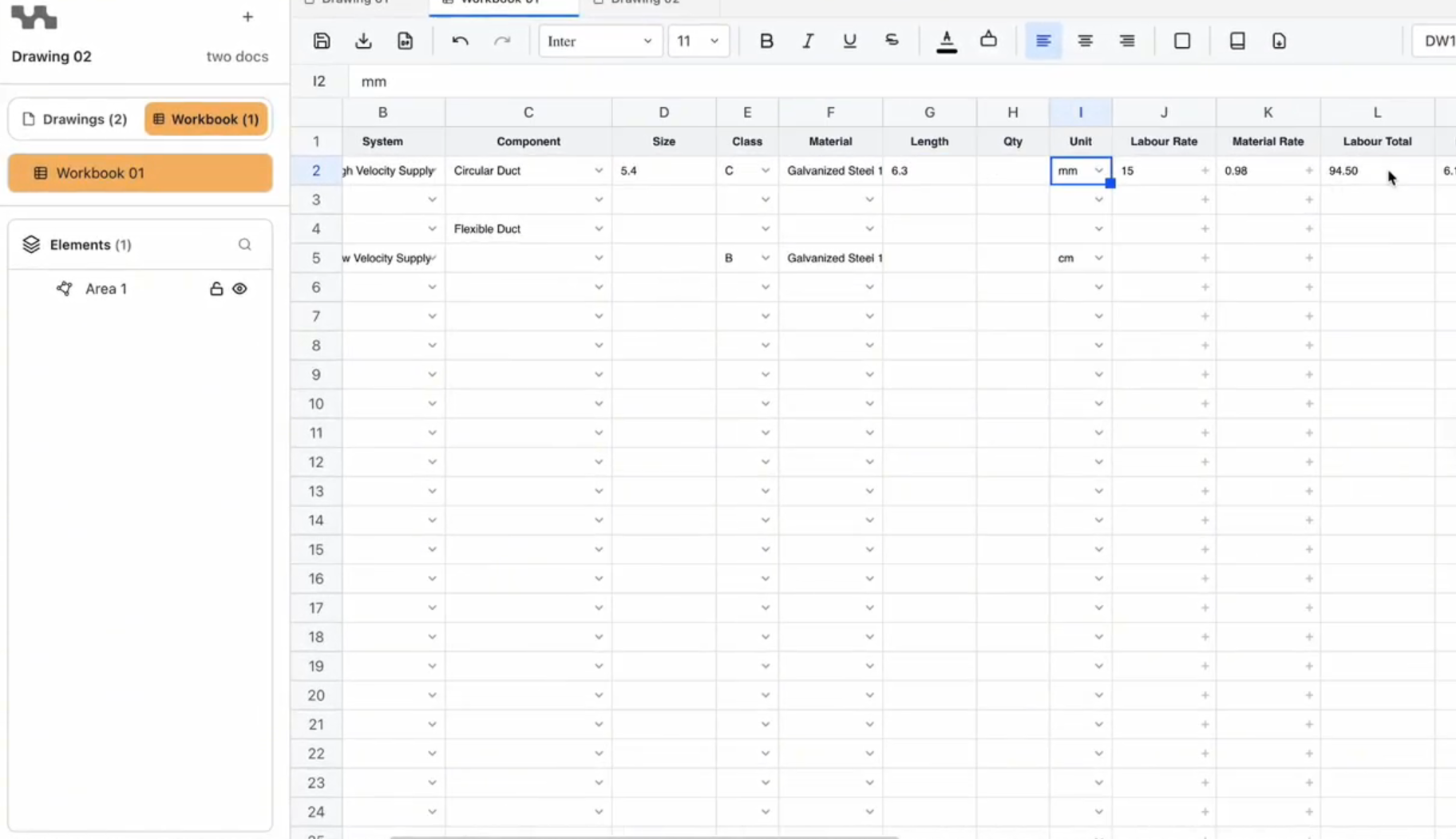
The IMS process for projects like this includes a week-one architecture decision about how the system needs to grow, not just what it needs to do at launch. For MeasureAI, that meant building the classification layer as a trade-agnostic framework — one that can be extended to plumbing, electrical, or any other trade that works from 2D PDF drawings — without rebuilding the detection and OCR layers from scratch.
What Does AI Construction Takeoff Software Actually Need to Get Right?
This question comes up for anyone evaluating or building in this space. Based on what we built for MeasureAI, a serious system needs to solve three things reliably:
Reliable pre-processing. Scale detection and drawing parsing have to work on real-world drawings, not idealized training examples. If the system can't accurately interpret the input, no amount of model sophistication downstream produces a usable output. This is where most systems that demo well start to fail in production.
Separation of concerns in the AI layer. Detection, classification, and annotation extraction are structurally different tasks. Trying to solve all three with a single model produces a system that's mediocre at all three. An ensemble approach — each model optimized for its specific task — produces better accuracy on each layer and makes the overall system easier to improve over time.
A human review interface that's part of the design, not an afterthought. The goal of AI construction takeoff software isn't to eliminate the estimator. It's to direct their attention to the decisions that actually require human judgment. A good system produces a confidence-scored output and surfaces low-confidence items for review. A bad system either makes all the decisions for the user or makes none of them.
What Building MeasureAI Taught Us About AI in Construction
The gap between demo and production in vertical AI
The construction industry has a growing list of AI-driven solutions entering the market — platforms for estimating, scheduling, risk management, and document review. Most of them work well on the demonstrations their vendors have prepared.
The harder problem is whether they work on the drawing a contractor uploaded at 11pm from a project that has its own symbol conventions, its own annotation style, and three revisions that weren't properly version-controlled.
That's where the Bug Bash matters. Two weeks before every delivery, our team and the client sit down and actively try to break the product — throwing edge cases at it, uploading drawings that stress the system, looking for failure modes before real users find them. For MeasureAI, this process identified several annotation-handling edge cases that the standard test set hadn't covered. Those got resolved before launch, not after.
Why domain-specific training data is the real moat
General-purpose computer vision models know what objects look like. They don't know what a DW144 hanger bracket calculation looks like on a UK mechanical drawing at 1:50 scale, or how a specific regional standards body annotates duct sizing.
That domain-specific knowledge — built through real drawings, real component libraries, and real feedback from HVAC professionals — is what separates a working system from a research project. It can't be bought. It has to be built. And it compounds over time as the system processes more drawings and the training data grows.
The Bigger Picture
The construction industry loses an estimated $31 billion annually to poor project data and rework caused by inaccurate estimates. AI construction takeoff software — built properly, for a specific trade, with production requirements in mind — directly addresses that waste.
MeasureAI is one example of what that looks like in practice: a multi-model architecture built for a specific domain, designed to be accurate enough for commercial use, and architected from day one to grow beyond its initial scope.
We also built CaseBench using a similar approach — vertical AI for a domain with specific data structures and domain expertise requirements, where the architecture decisions in week one determined what the system could become.
If you're building something similar — vertical AI for an industry that still runs on manual workflows — the architecture decisions matter more than the model selection. Imaginary Space builds these systems. That's what we do.