Why Most AI Products Fail After Launch, And What Production-Ready Actually Means
Why Most AI Products Fail After Launch — And What Production-Ready Actually Means
The demo worked. Investors were convinced. The product launched. Six months later, it's dead.
This is the pattern nobody talks about when discussing AI development failure rates. Most post-mortems blame the idea, the market, or the funding. Almost none of them name what actually broke: the product was never built to survive production in the first place.
Recent research from RAND Corporation puts the overall AI project failure rate above 80% — twice the failure rate of traditional technology projects. A 2025 S&P Global survey found that 42% of companies abandoned most of their AI initiatives, up from 17% the year before. The average organization scrapped 46% of AI proof-of-concepts before they reached production.
The technology isn't the problem. The approach is.
After shipping 50+ AI products at Imaginary Space — for VC-backed startups and enterprise teams at companies like Meta and Siemens — we've seen what separates the products that survive from the ones that don't. The difference isn't talent. It isn't budget. It's a set of specific decisions made (or not made) in the first weeks of a build.
This post names them.
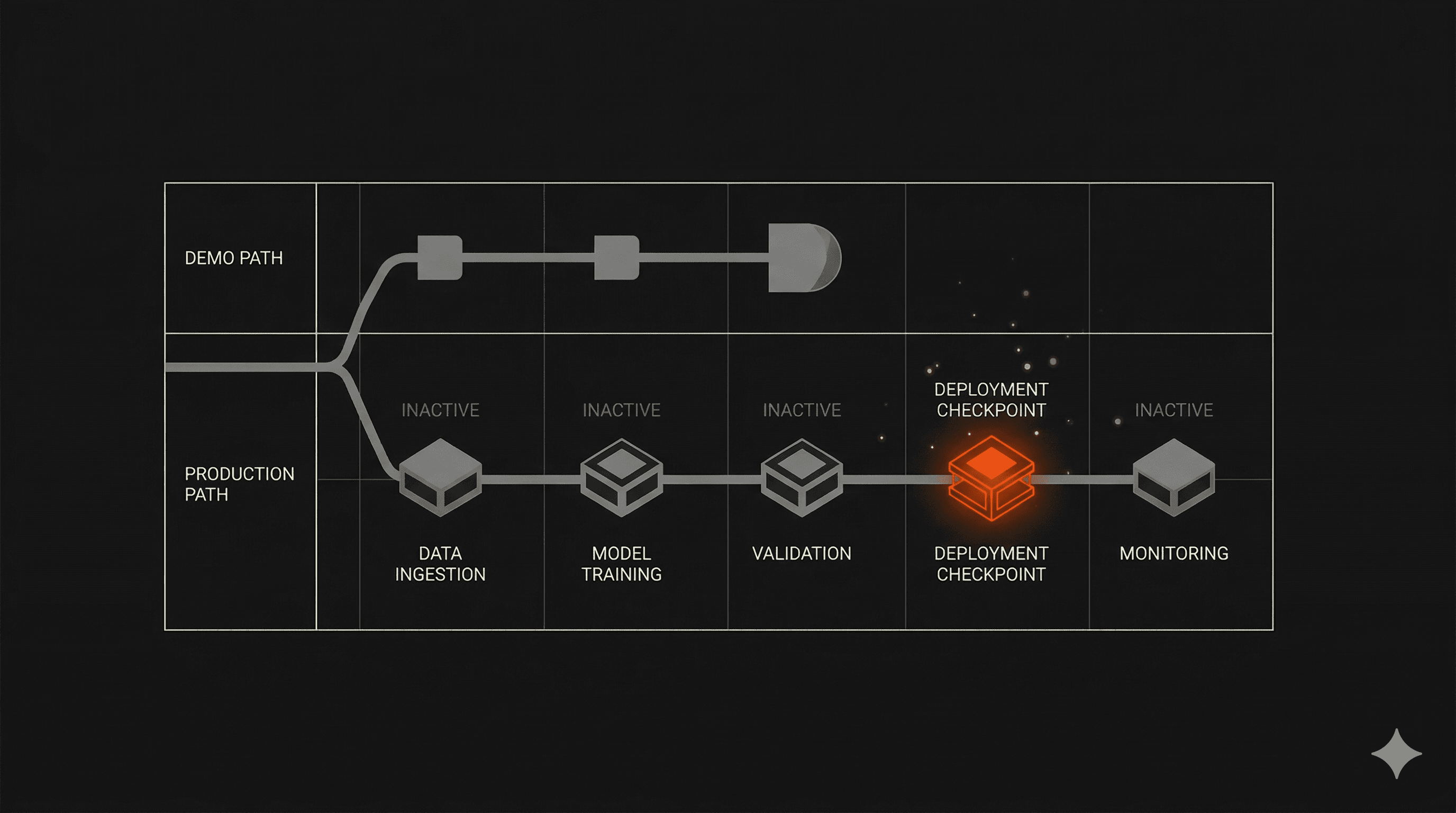
The demo-to-production gap is where most AI products die
What "working" means in a demo vs. in the wild
A demo runs on clean data, ideal conditions, and a controlled environment. Production means messy inputs, real user behavior, edge cases the team never anticipated, uptime requirements, and clear fallback behavior when the model is wrong.
These are fundamentally different problems. A product that handles the first has not been tested for the second.
Analysis of 125 MVP projects found that 68% stalled or collapsed within six to nine months after launch. Not before it. The failure happened after release, when real usage exposed the gap between what the product promised and what it could actually do at scale.
AI-specific products amplify this problem. Models need monitoring. Data pipelines need versioning. Feedback loops must exist from day one. Without operational thinking built into the initial architecture, AI features degrade silently. The product looks the same from the outside. It's rotting from the inside.
The invisible architecture decisions made in week one
Most teams treat architecture as something that gets formalized later. First, build the thing. Then make it solid.
That order is the mistake.
The architecture decisions made in the first week of a project determine whether it can scale, whether it can be maintained, and whether it can absorb the real-world complexity that no spec document fully anticipates. Reversing those decisions later doesn't just cost time — it often requires rebuilding the product from scratch.
Real speed comes from three things: defining the right problem before writing a line of code, making critical architecture decisions in week one, and knowing exactly what not to build. That sequence, done right, is what makes a four-week MVP possible without cutting corners.
Every time we've skipped the problem-definition step, the project cost twice the time and delivered half the value.
What production-ready actually means
Speed is a consequence of architecture, not of working harder
The phrase "move fast and break things" made sense in a world where breaking things was cheap. In AI product development, breaking things in production means losing users who won't come back, eroding trust that takes months to rebuild, and inheriting technical debt that blocks every improvement that follows.
Speed and quality are not tradeoffs. They're the same variable, set at the beginning of a project.
When the architecture is right, velocity isn't forced. It's built in. When it isn't, teams spend most of their time fixing problems they created earlier instead of building forward. That's not slow because of effort. It's slow because of structure.
Why vibe coding without engineering judgment breaks at scale
Vibe coding — using AI tools to generate code rapidly without deep architectural oversight — works. That's not the problem.
The problem is confusing the output of a coding assistant with production-grade engineering. AI can generate a function that works in isolation. It cannot make the judgment call about how that function will behave six months from now, under load, with data the team hasn't seen yet.
Production-ready means traditional software development standards — architecture that holds, code that scales — built with the speed advantage that AI gives you when you actually know how to use it. The key phrase is "when you actually know how to use it." Using AI as a skilled engineer is not the same as handing it the wheel without knowing where you're going.
MIT research found that 95% of generative AI pilots fail to scale. That number reflects what happens when the build process optimizes for the demo and not for what comes after it.
The specific process that keeps products alive
Why we try to break the product before users do
Two weeks before every delivery, we run a Bug Bash.
We sit down with the client and actively try to break the product. Not in a theoretical way — in a systematic, adversarial way. We push edge cases. We test failure modes. We simulate the inputs the product was never designed to handle. Then we do pen testing on critical features before anything ships.
The goal is not to find bugs. The goal is to find the assumptions that were never tested. Every product has them. Every team believes their product is solid until someone tries to use it in a way they didn't anticipate.
Finding those assumptions two weeks before delivery is a solvable problem. Finding them two weeks after launch is a crisis.
This process is why clients who work with us describe relief when the riskiest component wo