How We Built an AI Sprint Planning Tool That Replaced Standups
How We Built an AI Sprint Planning Tool That Replaced Standups how-we-built-ai-sprint-planning-tool-flor-work AI product development, sprint planning, engineering tools, AI agent, case study
Engineering teams don't have an execution problem. They have a coordination problem that eats into execution time.
The average engineer spends close to 40% less time coding because of sprint planning, standups, and status updates. Not because they're disorganized. Because the tools they use to stay aligned were built for a different era, one where coordination required human intervention at every step.
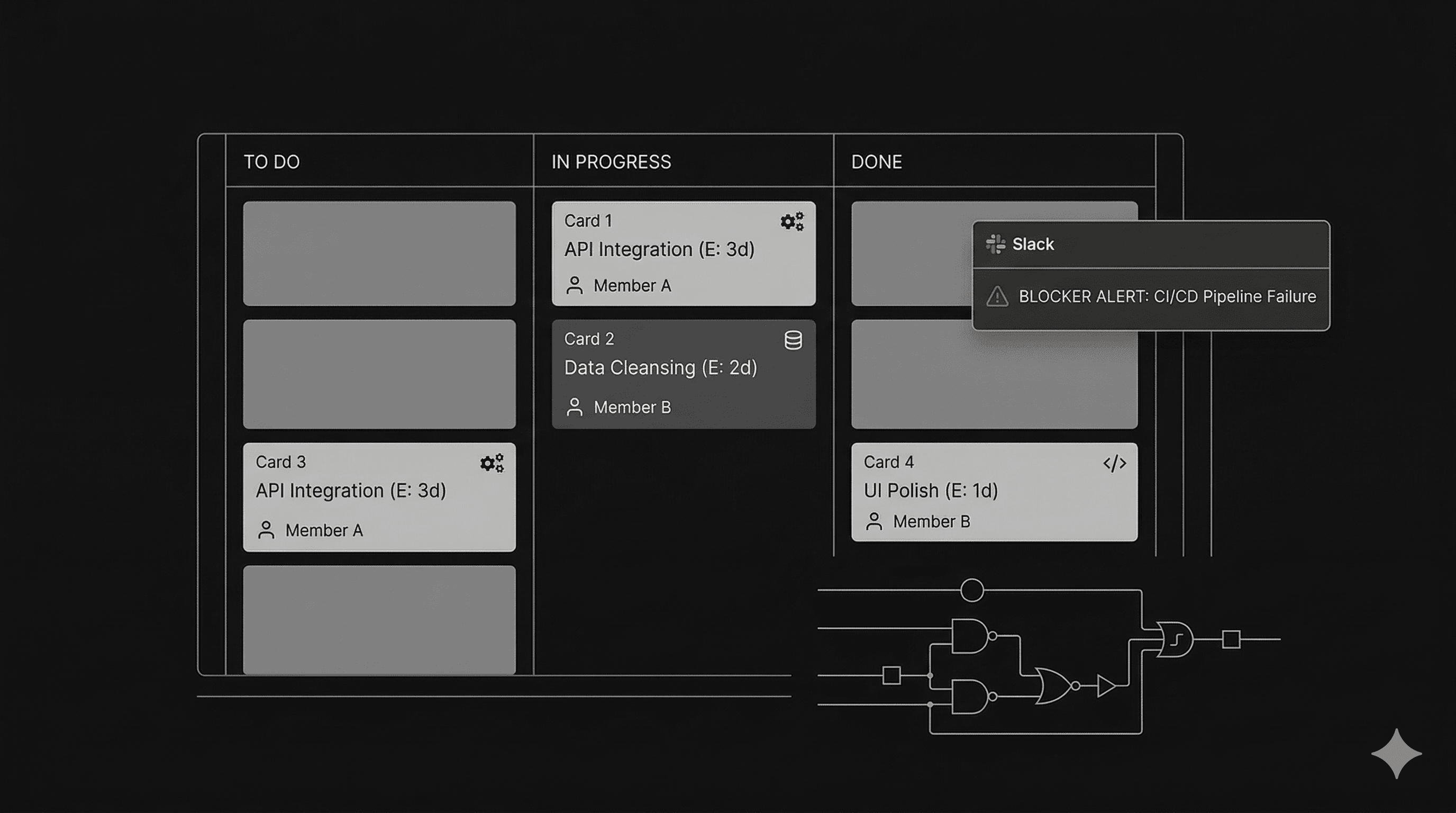
Flor.work starts from a different premise: the best project management is the kind you never think about. It's an AI agent that generates sprint plans in seconds, assigns tasks by skill and capacity, detects blockers before they escalate, and keeps teams in sync through Slack. No standups required.
This is how we built it, what we decided to cut, and why the result is 3x faster sprint planning and 40% less meeting time for the teams using it.
The Real Cost of Sprint Planning Nobody Talks About
It's not the meeting. It's everything around it.
Sprint planning has a visibility problem. When teams measure the cost of coordination overhead, they count the meeting. They don't count the preparation before it, the follow-up after it, the Slack threads clarifying what was decided, or the standups filling the gaps the planning session left open.
That's where the real time goes. Tasks fall through the cracks not because nobody cared, but because the system for tracking them depends on human memory and manual updates across too many tools.
Recent research on AI-assisted agile workflows points to teams reporting up to 40% faster release cycles once AI handles the coordination layer. The gain isn't from engineers working harder. It's from removing the translation gap between what needs to happen and what actually gets tracked.
What 40% fewer coding hours actually means at scale
For a team of 10 engineers, 40% less coding time is four engineers who aren't engineering. At a $150k average salary, that's $600k a year in salaries spent on process, not product.
The problem compounds in teams without a dedicated PM. They face a real choice: move fast and lose visibility, or stay organized and lose speed. Flor.work was built for exactly that situation.
What Flor.work Does (And What It Doesn't)
An AI agent, not another dashboard
The distinction matters. Most project management tools add a layer on top of existing work. They require someone to update them, maintain them, and enforce adoption. Flor.work is an agent, meaning it acts on the system instead of waiting for the system to be fed.
It plugs into GitHub, Jira, Linear, and Notion, reading the state of work from where it already lives. It generates sprint plans from that context, assigns tasks based on skill and current capacity, and reports progress through Slack without requiring anyone to log into another interface.
The goal from the start was zero new habits for the engineering team. The product had to work within the tools they already used.
How task assignment at 95% accuracy actually works
Task assignment sounds simple until you try to automate it. The naive version assigns work randomly or by availability alone. That breaks immediately when you have a backend engineer getting frontend tickets, or a junior dev getting something that requires three dependencies to be resolved first.
Flor.work combines skill mapping with capacity data and historical context from the connected tools. It knows who has shipped similar work before, who has bandwidth this sprint, and what's blocked. The 95% accuracy rate on AI-generated assignments comes from that combination, not from any single signal in isolation.
Automated dependency mapping reduces sprint disruptions by around 30% in teams that implement it. Flor.work does this by detecting blockers before they escalate, surfacing them in Slack before they become missed deadlines.
How We Built It: The Decisions That Mattered
Why Slack, not a new interface
The first real product decision was where the agent would live. The obvious path was a dedicated interface. A dashboard with sprint boards, assignment views, reporting panels. Clean, fully branded, easy to demo.
We cut it.
An interface requires adoption. Adoption requires habit change. Habit change in an engineering team is one of the hardest things to ship. If the agent required engineers to check a new tool to know what they were supposed to be working on, the adoption rate would tell us everything we needed to know about how useful it actually was.
Slack is already open. Engineers already respond to Slack. Making Flor.work Slack-native meant the product's utility didn't depend on behavior change. The team gets updates, assignments, and blocker alerts in the channel they're already in.
Integrations first, intelligence second
The second decision was sequencing. A common mistake in AI product development is building the intelligence layer before the data layer is solid. The model can only be as good as the context it has access to.
How we run every build at Imaginary Space starts with architecture decisions in week one. For Flor.work, that meant prioritizing the integration layer: GitHub, Jira, Linear, Notion, all connected and readable before any sprint generation logic was written.
Only once the data was clean and reliable did we build the agent on top of it. This sequencing is why the accuracy numbers held up. Garbage in, garbage out. The reverse is also true.
The pod that built Flor.work ran the same structure we use across all 50+ products: two engineers, a PM, and a designer, led by a senior engineer who set the technical standard from day one. Two weeks before delivery, we ran a Bug Bash, sitting with the client and actively trying to break the product before real users did. Then pen testing on critical features. Then delivery.
What 500+ Teams Shipping Faster Actually Looks Like
From sprint planning in days to seconds
The 3x faster sprint planning number comes from removing the preparation work that happens before the meeting, not just the meeting itself.
With Flor.work, the sprint plan is generated automatically from the connected tools. The backlog is read. Capacity is assessed. Tasks are assigned. The team reviews the plan in Slack, makes adjustments if needed, and moves. What previously required a half-day of grooming and a 90-minute planning session now takes minutes.
Research across teams using AI for project coordination shows that 44% of project practitioners expect to complete more projects with the same capacity once the coordination layer is handled by AI. Flor.work is that layer for engineering teams specifically.
The blocker detection piece nobody expected to matter most
When we scoped Flor.work, blocker detection was a secondary feature. Sprint planning was the headline. That's what clients asked for. That's what the product was named around.
Six months in, blocker detection is what teams talk about.
The reason is simple: sprint planning happens once per sprint. Blocker detection happens continuously. A task that gets stuck on day two of a two-week sprint has twelve days to cascade into something worse if nobody surfaces it. Flor.work catches it early and flags it in Slack before it becomes a missed deadline.
That's the difference between a tool that helps you plan and a tool that helps you ship.
Is an AI Sprint Planning Agent the Right Build for Your Team?
This depends on two things: where the coordination overhead actually lives, and what your team's existing stack looks like.
If your team is using GitHub and at least one of Jira, Linear, or Notion, the integration layer is already available. The agent has somewhere to read from. If your team is coordinating primarily in Slack, the output channel is already in place. In that combination, the build makes sense.
Where it doesn't make sense is teams that don't have a consistent tooling baseline. An AI agent that reads from three different systems maintained differently by three different people is not going to produce reliable sprint plans. The data hygiene has to come first.
The other consideration is team size. Flor.work was built for teams shipping actively without dedicated PM resources. Once a team is large enough to have a PM layer doing this work well, the marginal value of the agent drops. The product earns its keep in the 5-to-25 engineer range, where coordination overhead is real and dedicated coordination resources are either absent or thin.
What We'd Build Differently
The integration complexity we underestimated
Every tool has its own data model. GitHub structures work as issues and pull requests. Jira uses epics, stories, and subtasks. Linear has its own hierarchy. Notion can be anything. Getting a coherent view of sprint state across all four requires more normalization logic than it looks like from the outside.
We scoped the integration layer correctly in terms of time. We underestimated the edge cases. Partial integrations where a team uses GitHub but not Linear, or Notion but not Jira, require different logic paths than the clean four-tool scenario. Building those paths in after the fact costs more than building them in from the start.
Enterprise security from day one, not as an afterthought
Flor.work has enterprise-grade security. It didn't start that way. The initial build treated security as a phase-two concern, which is a common mistake in fast-moving product development.
For a tool that reads from GitHub repositories and project management systems, security isn't optional for enterprise adoption. We shipped it correctly, but the rework cost us time we could have avoided with earlier architecture decisions. The lesson is the same one that shows up across AI-native builds like MeasureAI: production requirements need to be first-class concerns from week one, not retrofits.
The Coordination Layer Is the Next Product Problem
The best engineering teams in the next two years won't be the ones with the most engineers. They'll be the ones that figured out coordination is a product problem, not a process problem. You don't fix it with better rituals or more meetings. You fix it with a system that handles the coordination layer automatically, so the team can stay focused on the work that actually ships.
That's what Flor.work does. And it's the category of problem we find ourselves building for more and more often.
Imaginary Space is an AI-native product studio. We turn ideas into production-ready products, with an average MVP timeline of four weeks. If you're building something that needs to move, book a discovery call.

